
[Kafka] 카프카(Kafka) 커넥트와 커넥터
Kafka Connect
카프카 커넥트는 Kafka Connect라는 분산 데이터 통합 플랫폼으로 다양한 소스와 대상 시스템 간의 데이터 이동을 지원하는 오픈소스 프로젝트입니다. Kafka Connect는 대부분의 경우 데이터 소스와 대상 시스템 간의 중개 역할을 하면서 이를 위한 일련의 Connector를 제공합니다.
Kafka Connect는 대규모 데이터 이동 및 데이터 통합 작업을 지원하며 대용량의 데이터를 처리할 수 있도록 설계되었습니다. 또한, Kafka Connect는 확장성이 우수하며 쉽게 구성하고 운영할 수 있는 기능을 제공합니다.
Kafka Connect의 구성요소는 크게 Connectors, Tasks, Converters, Worker, REST API로 구성됩니다. Connector는 데이터 소스 및 대상 시스템에 대한 연결을 설정하는 구성요소이며, 여러 개의 Task를 가질 수 있습니다. Task는 Kafka topic의 특정 파티션에 대한 데이터 이동을 수행하는 단위입니다. Converter는 Connector가 데이터를 변환할 때 사용되는 클래스로, 데이터 변환을 위한 로직을 담고 있습니다. Worker는 Kafka Connect에서 Connector와 Task의 실행을 관리하고, 자원 할당, 로그 처리 등의 역할을 수행합니다. REST API는 Kafka Connect 클러스터를 관리하기 위한 API를 제공합니다.
Kafka Connector
카프카 커넥터는 카프카와 다른 시스템 사이의 데이터 이동을 위해 구성 가능한 플러그인 모듈입니다. 카프카 커넥트 플랫폼에서는 데이터 소스와 데이터 대상을 모두 지원합니다. 커넥터는 데이터를 추출하여 카프카로 보낼 수도 있고 카프카에서 데이터를 가져와 다른 시스템으로 전송할 수도 있습니다.
카프카 커넥터는 이러한 작업을 수행하는데 필요한 다양한 기능과 유틸리티를 제공합니다. 예를 들어 커넥터는 데이터 변환 및 필터링, 데이터 포맷 변환, 스키마 레지스트리 연동 등을 지원합니다.
카프카 커넥터는 카프카와 다른 시스템 간의 데이터 이동을 단순화하며 일반적으로 사용되는 데이터 전송 시나리오를 쉽게 처리할 수 있도록 지원합니다. 또한 커넥터는 스케일 아웃 가능하며 분산 환경에서도 안정적으로 동작합니다.
카프카 커넥터는 다양한 종류의 커넥터를 지원합니다. 예를 들어 데이터베이스 커넥터, 파일 커넥터, 메시징 시스템 커넥터, 클라우드 서비스 커넥터 등이 있습니다. 이러한 커넥터를 사용하면 카프카와 다른 시스템 간의 데이터 이동을 쉽게 구성할 수 있습니다.
커넥터는 JSON 형식으로 작성되어 있으며 이를 통해 쉽게 구성할 수 있습니다. 또한, 커넥터는 REST API를 통해 관리되며 이를 통해 커넥터의 실행, 일시 중지, 재시작 등을 수행할 수 있습니다.
커넥터는 카프카의 높은 처리량, 낮은 지연 시간 및 분산 처리 능력을 활용하여 대규모 데이터 이동을 처리할 수 있습니다. 이를 통해 비즈니스 요구 사항에 따라 더 많은 데이터를 처리하고 빠르게 대응할 수 있습니다.
MongoDB Sink Connector
MongoDB Sink Connector를 통해 카프카 토픽 데이터를 MongoDB로 전송할 수 있습니다.
우선적으로 아래 링크에 접속하여 MongoDB Sink Connector 설치합니다.
https://www.confluent.io/hub/mongodb/kafka-connect-mongodb

“name”: 커넥터의 이름 지정
“connector.class”: 카프카 커넥터 클래스 지정
“writemodel.strategy”: Write 방식 지정, ReplaceOneDefaultStrategy를 사용하여 도큐먼트가 존재하면 대체하도록 함
“document.id.strategy”: 도큐먼트의 고유 ID 생성 방식 지정, 카프카 메시지 value 값에서 직접 제공하도록 설정함
“post.processor.chain”: 레코드 전송 전 후처리 작업을 적용할 수 있는 프로세서 체인을 지정, DocumentIdAdder를 사용하여 문서 ID를 추가함
“document.id.strategy.overwrite.existing”: 기존 ID가 있으면 덮어쓸 것인지 여부 지정, true를 사용하여 덮어쓰도록 설정
“topics”: 카프카에서 데이터를 읽을 토픽의 이름 지정
“connection.uri”: MongoDB 연결 URI를 지정, 10.70.171.105:27017에 있는 MongoDB에 연결
“database”: 데이터를 저장할 MongoDB의 데이터베이스 이름 지정
“collection”: 데이터를 저장할 MongoDB의 컬렉션 이름 지정
“tasks.max”: 실행할 태스크의 수를 지정, 데이터 양, 하드웨어 성능, 네트워크 대역폭 등 여러 요소에 따라 다르지만 일반적으로 파티션 수만큼 지정하여 각 파티션을 처리할 수 있는 커넥터 태스크를 생성함
“group.id”: 컨슈머 그룹의 ID를 지정, 카프카에선 하나의 토픽이 여러 개의 파티션으로 분할될 수 있고 각 파티션은 하나 이상의 컨슈머 그룹에 해당될 수 있음
“max.batch.size”: 배치 처리 크기를 지정, 0을 사용하여 제한을 두지 않음
“delete.on.null.values”: null 값을 삭제할지 여부 지정, false를 사용하여 삭제하지 않도록 설정
“key.converter”: 키의 데이터 형식을 변환할 클래스 지정,StringConverter를 사용하여 문자열 형식을 변환
“key.converter.schemas.enable”: 키 스키마 사용 여부 지정, false를 사용하여 스키마를 사용하지 않도록 설정
“value.converter”: 값의 데이터 형식을 변환할 클래스를 지정, StringConverter를 사용하여 문자열 형식을 변환
“value.converter.schemas.enable”: 값 스키마 사용 여부를 지정, false를 사용하여 스키마를 사용하지 않도록 설정
“value.converter.transforms”: “hoist_id_field”: value의 ID를 사용
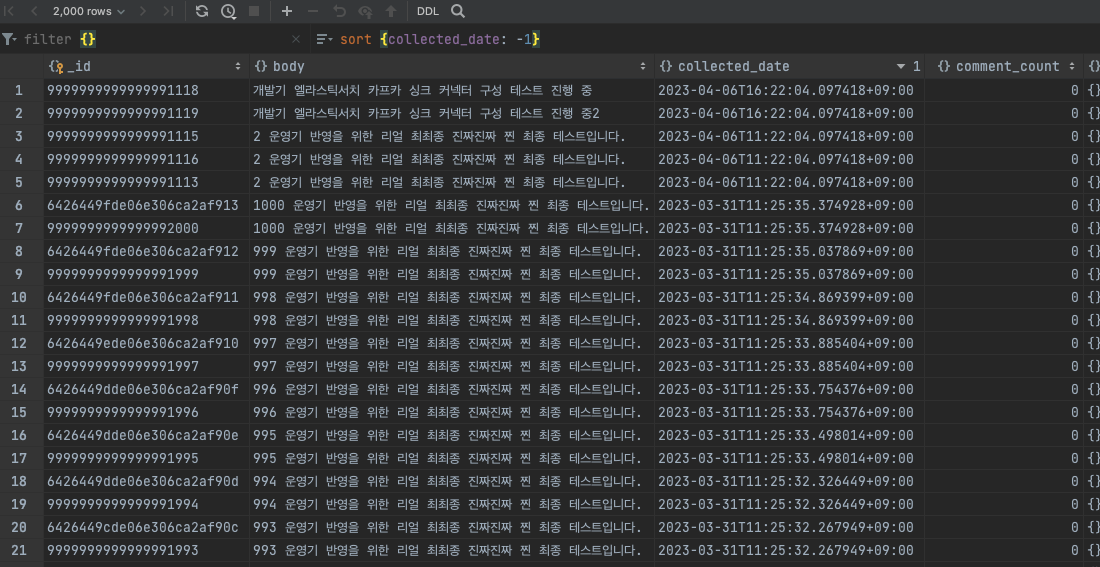
커넥터 생성 후 토픽의 데이터가 몽고DB에 전송된 모습
ElasticSearch Sink Connector
ElasticSearch Sink Connector를 통해 카프카 토픽을 ElaticSearch로 전송할 수 있음 https://www.confluent.io/hub/confluentinc/kafka-connect-elasticsearch 해당 링크에서 엘라스틱 서치 싱크 커넥트 다운로드 후 커넥터 생성
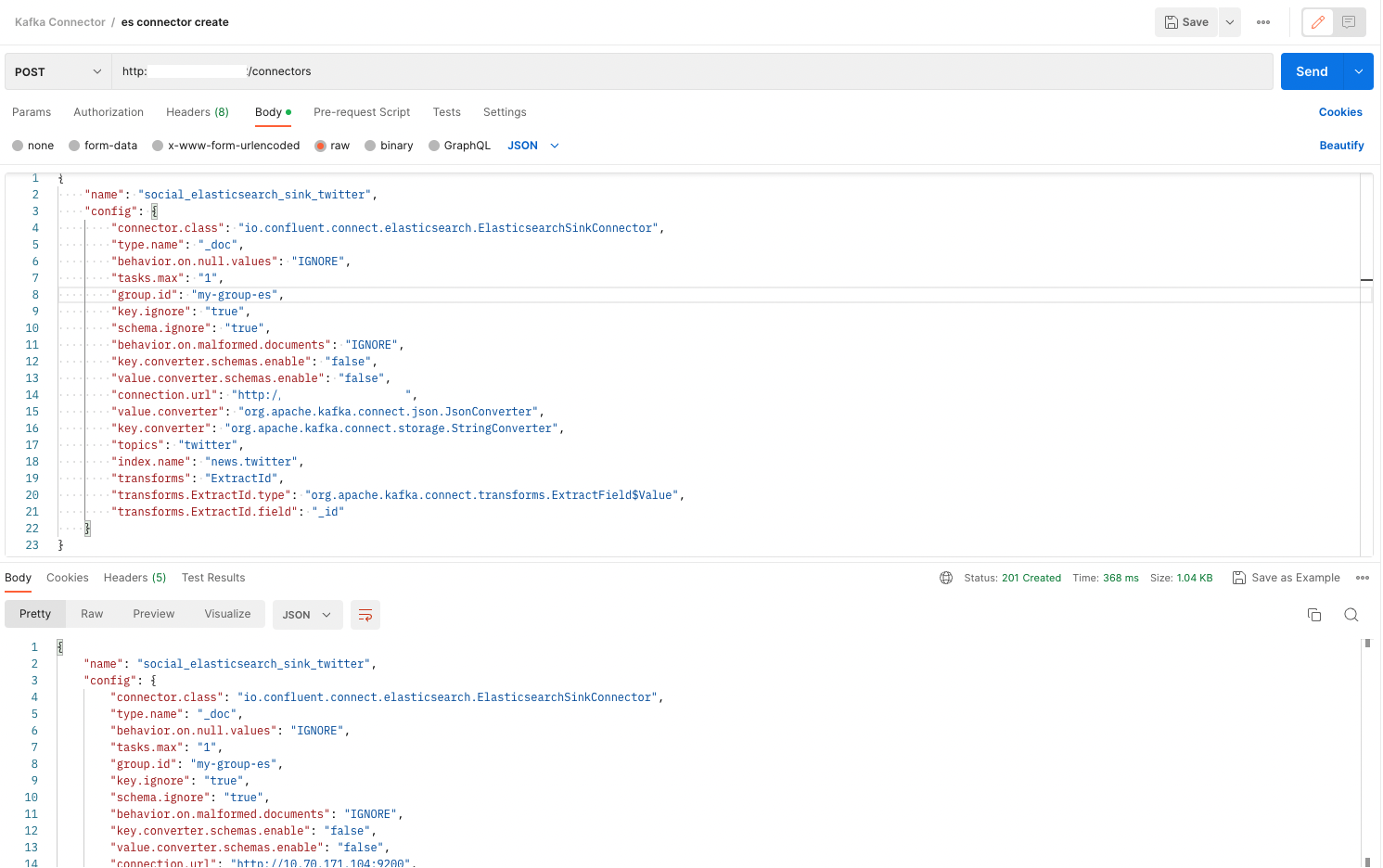
“name”: “social_elasticsearch_sink_twitter” - 커넥터 인스턴스의 이름 지정
“connector.class”: “io.confluent.connect.elasticsearch.ElasticsearchSinkConnector” - 사용할 커넥터 클래스를 지정 여기서는 Elasticsearch Sink 커넥터 사용
“type.name”: “_doc” - Elasticsearch의 mapping type을 지정 _doc은 기본값
“behavior.on.null.values”: “IGNORE” - 레코드 값이 null인 경우 무시하도록 설정
“tasks.max”: “1” - 최대 태스크 수를 지정 여기서는 1개의 태스크로 설정
“group.id”: “my-group-es” - 커넥터가 속한 컨슈머 그룹의 ID 지정
“key.ignore”: “true” - 레코드 키를 무시하도록 설정
“schema.ignore”: “true” - 스키마를 무시하도록 설정
“behavior.on.malformed.documents”: “IGNORE” - 문서 형식이 잘못된 경우 무시하도록 설정
“key.converter.schemas.enable”: “false” - 키 컨버터 스키마 사용 비활성화
“value.converter.schemas.enable”: “false” - 값 컨버터 스키마 사용 비활성화
“connection.url”: “http://10.00.000.000:9200” - Elasticsearch 클러스터의 URL 지정
“value.converter”: “org.apache.kafka.connect.json.JsonConverter” - 값에 대한 컨버터 클래스를 지정 여기서는 JSON 컨버터 사용
“key.converter”: “org.apache.kafka.connect.storage.StringConverter” - 키에 대한 컨버터 클래스를 지정 여기서는 문자열 컨버터 사용
“topics”: “twitter” - 커넥터가 처리할 Kafka 토픽 지정
“index.name”: “news.twitter” - Elasticsearch에 데이터를 전송할 인덱스의 이름 지정
“transforms”: “ExtractId” - 변환 작업의 이름 지정
“transforms.ExtractId.type”: “org.apache.kafka.connect.transforms.ExtractField$Value” - 변환 작업의 유형을 지정 여기서는 레코드의 값을 사용하여 필드를 추출하는 작업
“transforms.ExtractId.field”: “_id” - 추출할 필드의 이름 지정 여기서는 _id 필드를 추출 이렇게 하면 Kafka의 레코드 값에서 _id 필드를 가져와 Elasticsearch의 문서 _id로 사용한다
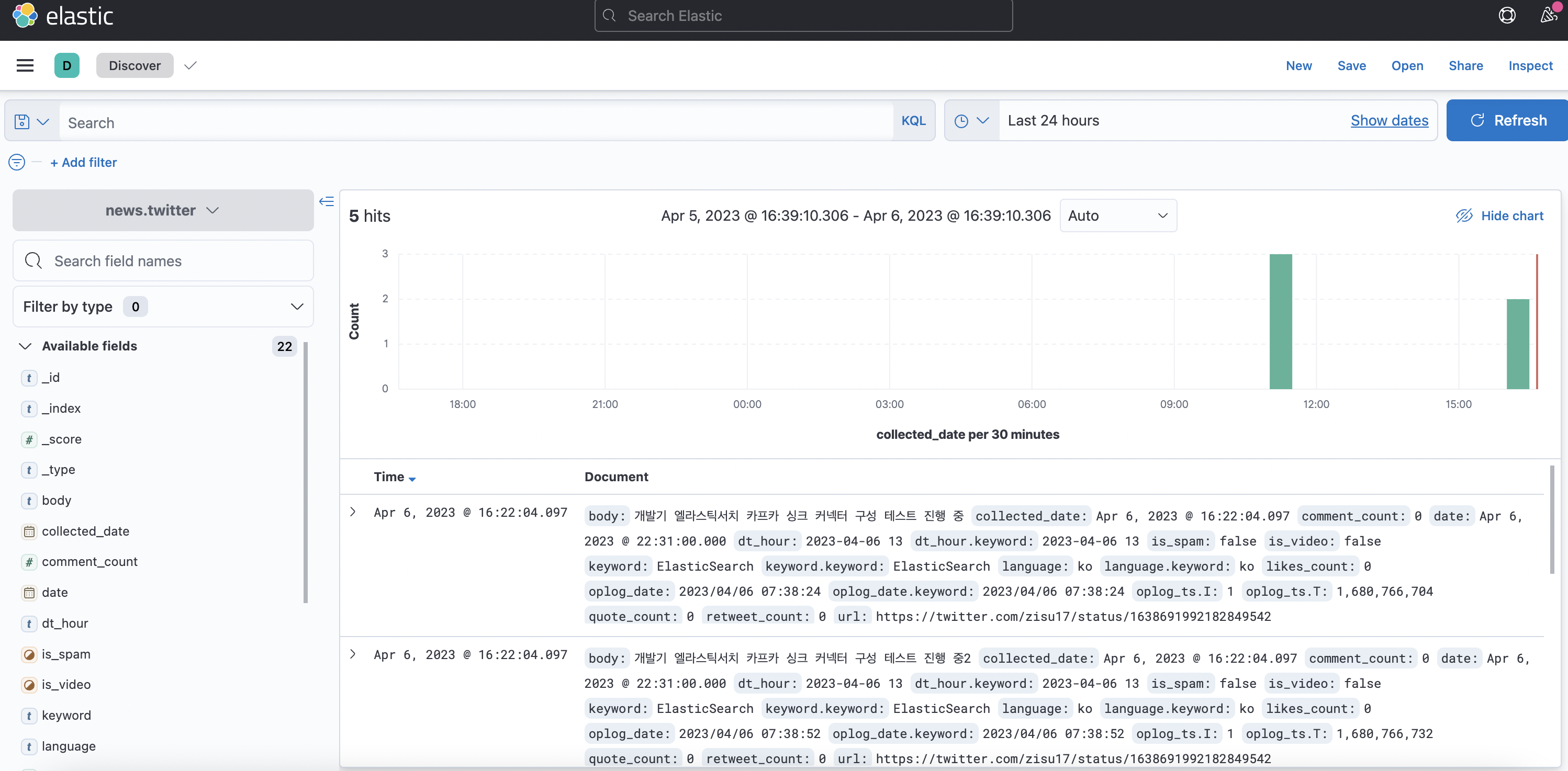
커넥터 생성 후 토픽의 데이터가 엘라스틱 서치에 전송된 모습
Leave a comment